import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import warnings
import os
warnings.filterwarnings('ignore')
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 创建保存预测结果的目录(如果不存在)
output_dir = r"C:\Users\PC\Desktop\降水预测结果"
os.makedirs(output_dir, exist_ok=True)
# 读取降水量数据
data_path = r"C:\Users\PC\Desktop\数据驱动清洗后数据\2013-2023monthly_avg_precipitation.csv"
df = pd.read_csv(data_path)
# 转换日期格式
date_column = None
for col in df.columns:
if 'date' in col.lower() or '时间' in col:
date_column = col
break
if date_column is None:
raise ValueError("无法在数据中找到日期列,请检查数据集格式。")
df['date'] = pd.to_datetime(df[date_column])
# 自动检测降水量列名
precipitation_column = None
possible_names = ['precipitation', '降水量', 'rainfall', 'precip', '降水']
for col in df.columns:
if any(name in col.lower() for name in possible_names):
precipitation_column = col
break
if precipitation_column is None:
raise ValueError("无法在数据中找到降水量列,请检查数据集格式。")
# 重命名为统一的 'precipitation'
df.rename(columns={precipitation_column: 'precipitation'}, inplace=True)
# 降水量列——数值类型
df['precipitation'] = pd.to_numeric(df['precipitation'], errors='coerce')
# 设置日期为索引
df.set_index('date', inplace=True)
# 数据探索
print("数据基本信息:")
df.info()
# 检查缺失值
print("\n缺失值统计:")
print(df.isnull().sum())
# 填充缺失值(如果有)
if df['precipitation'].isnull().any():
print("\n警告:降水量列包含缺失值,将使用前向填充。")
df['precipitation'].fillna(method='ffill', inplace=True)
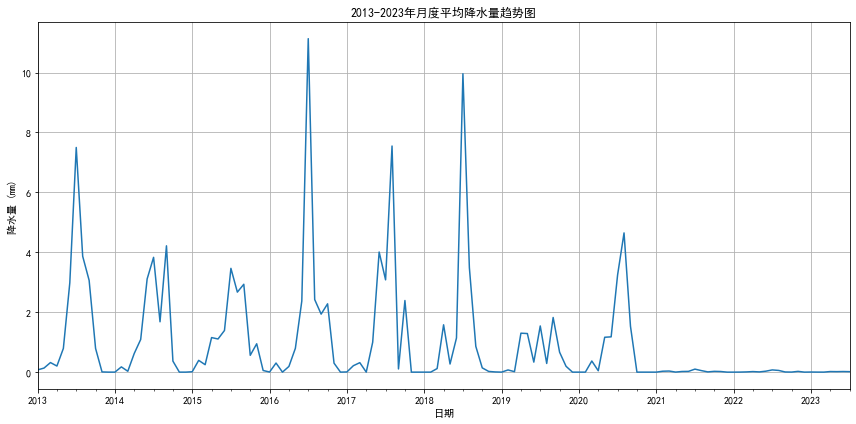
# 数据可视化 - 月度平均降水量趋势
plt.figure(figsize=(12, 6))
df['precipitation'].plot(title='2013-2023年月度平均降水量趋势图')
plt.xlabel('日期')
plt.ylabel('降水量 (mm)')
plt.grid(True)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, '1_月度平均降水量趋势图.png'))
plt.show()
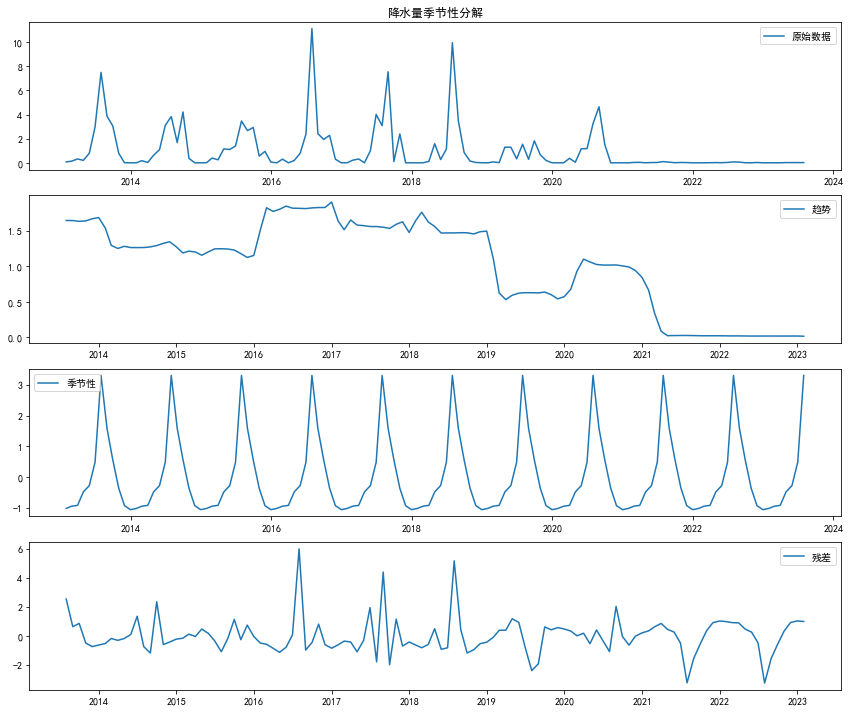
# 季节性分解
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(df['precipitation'], model='additive', period=12)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
# 数据可视化 - 季节性分解
plt.figure(figsize=(12, 10))
plt.subplot(411)
plt.plot(df['precipitation'], label='原始数据')
plt.title('降水量季节性分解')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(trend, label='趋势')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(seasonal, label='季节性')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(residual, label='残差')
plt.legend(loc='best')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, '2_降水量季节性分解图.png'))
plt.show()
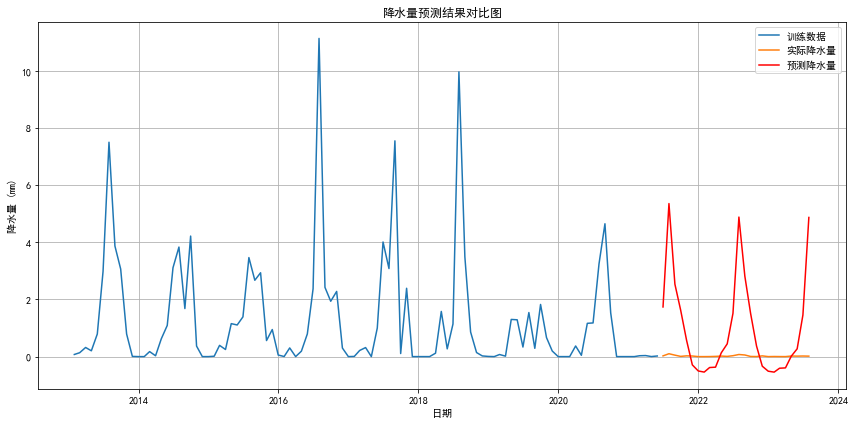
# 划分训练集和测试集
train_size = int(len(df) * 0.8)
train, test = df.iloc[:train_size], df.iloc[train_size:]
# ARIMA模型训练与预测
# 这里使用简单参数,实际应用中建议通过AIC/BIC等选择最优参数
model = ARIMA(train['precipitation'], order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
model_fit = model.fit()
# 预测测试集
predictions = model_fit.forecast(steps=len(test))
predictions.index = test.index
# 计算RMSE
rmse = np.sqrt(mean_squared_error(test['precipitation'], predictions))
print(f'\n测试集RMSE: {rmse:.2f} mm')
# 数据可视化 - 预测结果
plt.figure(figsize=(12, 6))
plt.plot(train['precipitation'], label='训练数据')
plt.plot(test['precipitation'], label='实际降水量')
plt.plot(predictions, label='预测降水量', color='r')
plt.title('降水量预测结果对比图')
plt.xlabel('日期')
plt.ylabel('降水量 (mm)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, '3_降水量预测结果对比图.png'))
plt.show()
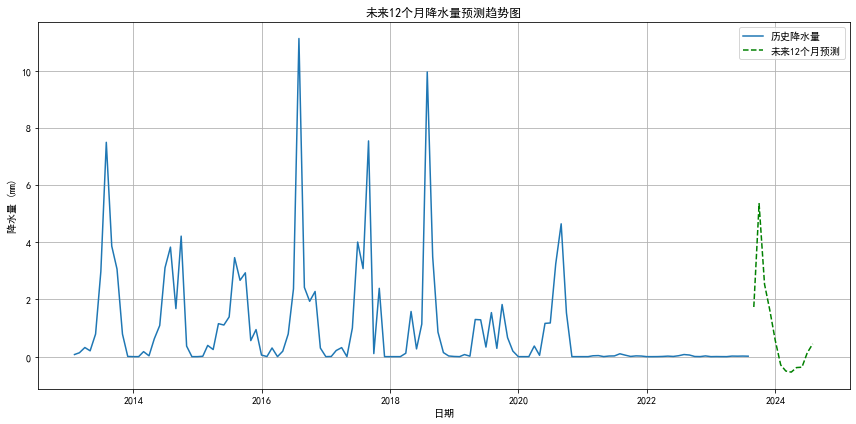
# 未来12个月的降水量预测
future_predictions = model_fit.forecast(steps=12)
future_dates = pd.date_range(start=df.index[-1], periods=13, freq='MS')[1:]
future_predictions.index = future_dates
# 数据可视化 - 未来预测
plt.figure(figsize=(12, 6))
plt.plot(df['precipitation'], label='历史降水量')
plt.plot(future_predictions, label='未来12个月预测', color='g', linestyle='--')
plt.title('未来12个月降水量预测趋势图')
plt.xlabel('日期')
plt.ylabel('降水量 (mm)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig(os.path.join(output_dir, '4_未来降水量预测趋势图.png'))
plt.show()
# 保存预测结果
save_path = os.path.join(output_dir, '未来12个月降水量预测.csv')
future_df = pd.DataFrame({
'date': future_dates,
'predicted_precipitation': future_predictions
})
future_df.to_csv(save_path, index=False, encoding='utf-8-sig')
print(f"\n未来12个月降水量预测已保存至 '{save_path}'")
# 保存模型评估结果
with open(os.path.join(output_dir, '模型评估报告.txt'), 'w', encoding='utf-8') as f:
f.write(f"降水量预测模型评估报告\n")
f.write(f"测试集RMSE: {rmse:.2f} mm\n\n")
f.write("模型参数:\n")
f.write(f"ARIMA: order=(1, 1, 1), seasonal_order=(1, 1, 1, 12)\n")
print(f"模型评估报告已保存至 '{os.path.join(output_dir, '模型评估报告.txt')}'")