***** NOTE: Your configuration may still support GUIs,
***** use the fixes below only after you try
***** running metagear's abstract_screener().
**
** Fix for Windows users:
** Update R (tcltk is now part of all new R builds).
** Fix for Mac users:
** Install xQuartz (X11) from https://www.xquartz.org/
***** setup supports data extraction from plots/figures [ FALSE ]
***** NOTE: EBImage package (Bioconductor) will be installed only
***** when a figure_* function is used.
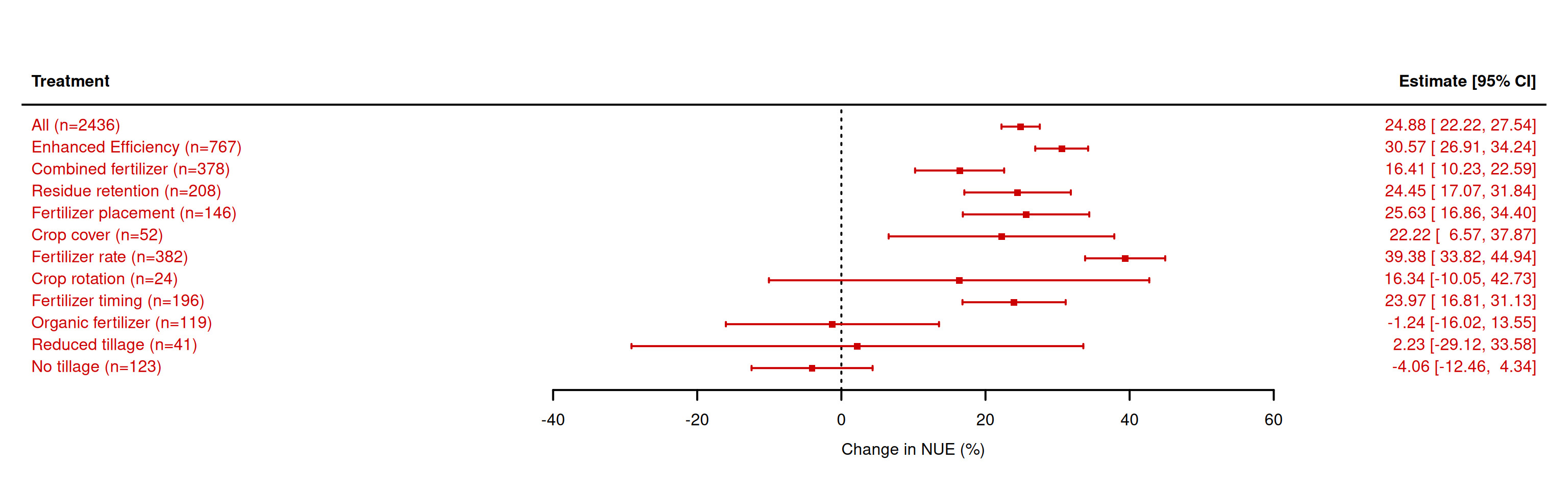
##################################### ROM (metafor) ##################################################### read datad1 <- readxl::read_xlsx('Source Data.xlsx',sheet ="Tables")d1 <-as.data.table(d1)#Supplement the standard deviation missing value_Common Methodd2<-d1CV_nuet_bar<-mean(d2$nuet_sd[is.na(d2$nuet_sd)==FALSE]/d2$nuet_mean[is.na(d2$nuet_sd)==FALSE])d2$nuet_sd[is.na(d2$nuet_sd)==TRUE]<-d2$nuet_mean[is.na(d2$nuet_sd)==TRUE]*1.25*CV_nuet_barCV_nuec_bar<-mean(d2$nuec_sd[is.na(d2$nuec_sd)==FALSE]/d2$nuec_mean[is.na(d2$nuec_sd)==FALSE])d2$nuec_sd[is.na(d2$nuec_sd)==TRUE]<-d2$nuec_mean[is.na(d2$nuec_sd)==TRUE]*1.25*CV_nuec_bar# clean up column namesd2 <-as.data.table(d2)setnames(d2,gsub('\\/','_',gsub(' |\\(|\\)','',colnames(d2))))setnames(d2,tolower(colnames(d2)))# calculate effect size (NUE)es21 <-escalc(measure ="ROM", data = d2, m1i = nuet_mean, sd1i = nuet_sd, n1i = replication,m2i = nuec_mean, sd2i = nuec_sd, n2i = replication )# convert to data.tablesd02 <-as.data.table(es21)# what are the treatments to be assessedd02.treat <-data.table(treatment =c('ALL',unique(d02$management)))# what are labelsd02.treat[treatment=='ALL',desc :='All']d02.treat[treatment=='EE',desc :='Enhanced Efficiency']d02.treat[treatment=='CF',desc :='Combined fertilizer']d02.treat[treatment=='RES',desc :='Residue retention']d02.treat[treatment=='RFP',desc :='Fertilizer placement']d02.treat[treatment=='RFR',desc :='Fertilizer rate']d02.treat[treatment=='ROT',desc :='Crop rotation']d02.treat[treatment=='RFT',desc :='Fertilizer timing']d02.treat[treatment=='OF',desc :='Organic fertilizer']d02.treat[treatment=='RT',desc :='Reduced tillage']d02.treat[treatment=='NT',desc :='No tillage']d02.treat[treatment=='CC',desc :='Crop cover']# a list to store the coefficientsout2 = out3 =list()# make a for loop to do a main analysis per treatmentfor(i in d02.treat$treatment){if(i=='ALL'){# run without selection to estimate overall mean r_nue <-rma.mv(yi,vi, data=d02,random=list(~1|studyid), method="REML",sparse =TRUE) } else {# run for selected treatment r_nue <-rma.mv(yi,vi, data=d02[management==i,],random=list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list out2[[i]] <-data.table(mean =as.numeric((exp(r_nue$b)-1)*100),se =as.numeric((exp(r_nue$se)-1)*100),pval =round(as.numeric(r_nue$pval),4),label =paste0(d02.treat[treatment==i,desc],' (n=',r_nue$k,')') )}# convert lists to vectorout2 <-rbindlist(out2)# plot for NUEforest(x = out2$mean, sei = out2$se, slab=out2$label, psize=0.9, cex=1, sortvar=out2$label, xlab="Change in NUE (%)", header="Treatment", col="#CC0000", lwd=2)
Warning in plot.window(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy, type, ...): "sortvar" is not a graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in box(...): "sortvar" is not a graphical parameter
Warning in title(...): "sortvar" is not a graphical parameter
Warning in int_abline(a = a, b = b, h = h, v = v, untf = untf, ...): "sortvar"
is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in axis(...): "sortvar" is not a graphical parameter
Warning in mtext(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Rank Correlation Test for Funnel Plot Asymmetry
Kendall's tau = -0.3333, p = 0.1526
#egger’s testregtest(out2$mean, out2$se)
Warning: The 'vi' argument should be used to specify sampling variances,
but 'out2$se' sounds like this variable may contain standard
errors (maybe use 'sei=out2$se' instead?).
Regression Test for Funnel Plot Asymmetry
Model: mixed-effects meta-regression model
Predictor: standard error
Test for Funnel Plot Asymmetry: z = -1.9894, p = 0.0467
Limit Estimate (as sei -> 0): b = 36.9676 (CI: 17.6886, 56.2465)
# Meta-regression for main factors# do a first main factor analysis for log response ratio for NUE# update the missing values for n_dosed02[is.na(n_dose), n_dose :=median(d02$n_dose,na.rm=TRUE)]# # scale the variables to unit varianced02[,clay_scaled :=scale(clay)]d02[,soc_scaled :=scale(soc)]d02[,ph_scaled :=scale(ph)]d02[,mat_scaled :=scale(mat)]d02[,map_scaled :=scale(map)]d02[,n_dose_scaled :=scale(n_dose)]# what are the factors to be evaluatedvar.site <-c('mat_scaled','map_scaled','clay_scaled','soc_scaled','ph_scaled')var.crop <-c('g_crop_type','n_dose_scaled')var.trea <-c('fertilizer_type', 'crop_residue', 'tillage', 'cover_crop_and_crop_rotation', 'fertilizer_strategy')# i select only one example# the columns to be assessedvar.sel <-c(var.trea,var.crop,var.site)# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)# objects to store the effects per factor as wel summary stats of the meta-analytical modelsout1.est = out1.sum =list()# evaluate the impact of treatment (column tillage) on NUE given site propertiesfor(i in var.sel){# check whether the column is a numeric or categorical variable vartype =is.character(d02[,get(i)])# run with the main factor treatmentif(vartype ==TRUE){# run a meta-regression model for main categorial variable r_nue_1 <-rma.mv(yi,vi, mods =~factor(varsel)-1, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) } else {# run a meta-regression model for main numerical variable r_nue_1 <-rma.mv(yi,vi, mods =~varsel, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list: the estimated impact of the explanatory variable out1.est[[i]] <-data.table(var = i,varname =gsub('factor\\(varsel\\)','',rownames(r_nue_1$b)),mean =round(as.numeric(r_nue_1$b),3),se =round(as.numeric(r_nue_1$se),3),ci.lb =round(as.numeric(r_nue_1$ci.lb),3),ci.ub =round(as.numeric(r_nue_1$ci.ub),3),pval =round(as.numeric(r_nue_1$pval),3))# save output in a list: the summary stats collected out1.sum[[i]] <-data.table(var = i,AIC = r_nue_1$fit.stats[4,2],ll = r_nue_1$fit.stats[1,2],ll_impr =round(100* (1-r_nue_1$fit.stats[1,2]/r_nue_0$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(r_nue_0$sigma2)-sum(r_nue_1$sigma2))/sum(r_nue_0$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3) )}
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
# merge output into a data.tableout1.sum <-rbindlist(out1.sum)out1.est <-rbindlist(out1.est)# Meta-regression for main factors with interactions# make a function to extract relevant model statisticsestats <-function(model_new,model_base){ out <-data.table(AIC = model_new$fit.stats[4,2],ll = model_new$fit.stats[1,2],ll_impr =round(100* (1-model_new$fit.stats[1,2]/model_base$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(model_base$sigma2)-sum(model_new$sigma2))/sum(model_base$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3))return(out)}d02[tillage=='reduced', tillage :='no-till']d02[,fertilizer_type :=factor(fertilizer_type,levels =c('mineral','organic', 'combined','enhanced'))] d02[,fertilizer_strategy :=factor(fertilizer_strategy,levels =c("conventional", "placement","rate","timing"))]d02[,g_crop_type :=factor(g_crop_type,levels =c('maize','wheat','rice'))]d4 <-copy(d02)d4[,r4pl :=fifelse(fertilizer_strategy=='placement','yes','no')]d4[,r4ti :=fifelse(fertilizer_strategy=='timing','yes','no')]d4[,r4do :=fifelse(fertilizer_strategy=='rate','yes','no')]d4[,ctm :=fifelse(g_crop_type=='maize','yes','no')]d4[,ctw :=fifelse(g_crop_type=='wheat','yes','no')]d4[,ctr :=fifelse(g_crop_type=='rice','yes','no')]d4[,ndose2 :=scale(n_dose^2)]# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)r_nue_4 <-rma.mv(yi,vi,mods =~fertilizer_type + r4pl + r4ti + r4do + crop_residue + tillage + cover_crop_and_crop_rotation + n_dose_scaled + clay_scaled + ph_scaled + map_scaled + mat_scaled + soc_scaled+ soc_scaled : n_dose_scaled + ctm:r4pl + ctm + ctw + ctr + ctm:mat_scaled + ndose2 -1,data = d4,random =list(~1|studyid), method="REML",sparse =TRUE)
Warning: Redundant predictors dropped from the model.
# show stats and improvementsout =estats(model_new = r_nue_4,model_base = r_nue_0)
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
print(paste0('model improved the log likelyhood with ',round(out$ll_impr,1),'%'))
[1] "model improved the log likelyhood with 43.4%"
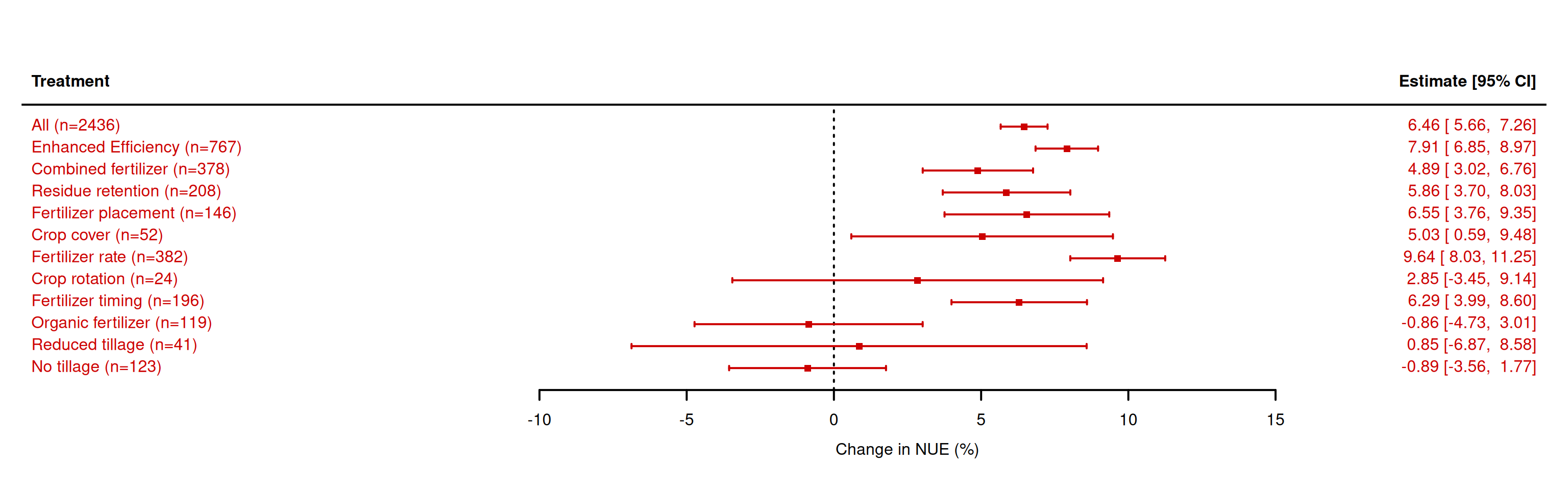
k <- r_nue_4$kwi <-1/r_nue_4$vivt <- (k-1) / (sum(wi) -sum(wi^2)/sum(wi))PR2 <- r_nue_0$sigma2 / (sum(r_nue_4$sigma2) + vt)##################################### MD (metafor) ##################################################### read datad1 <- readxl::read_xlsx('Source Data.xlsx',sheet ="Tables")d1 <-as.data.table(d1)# Supplement the SD when missingd2<-d1CV_nuet_bar<-mean(d2$nuet_sd[is.na(d2$nuet_sd)==FALSE]/d2$nuet_mean[is.na(d2$nuet_sd)==FALSE])d2$nuet_sd[is.na(d2$nuet_sd)==TRUE]<-d2$nuet_mean[is.na(d2$nuet_sd)==TRUE]*1.25*CV_nuet_barCV_nuec_bar<-mean(d2$nuec_sd[is.na(d2$nuec_sd)==FALSE]/d2$nuec_mean[is.na(d2$nuec_sd)==FALSE])d2$nuec_sd[is.na(d2$nuec_sd)==TRUE]<-d2$nuec_mean[is.na(d2$nuec_sd)==TRUE]*1.25*CV_nuec_bar# clean up column namesd2 <-as.data.table(d2)setnames(d2,gsub('\\/','_',gsub(' |\\(|\\)','',colnames(d2))))setnames(d2,tolower(colnames(d2)))# calculate effect size (MD)es21 <-escalc(measure ="MD", data = d2, m1i = nuet_mean, sd1i = nuet_sd, n1i = replication,m2i = nuec_mean, sd2i = nuec_sd, n2i = replication )# convert to data.tablesd02 <-as.data.table(es21)# what are the treatments to be assessedd02.treat <-data.table(treatment =c('ALL',unique(d02$management)))# what are labelsd02.treat[treatment=='ALL',desc :='All']d02.treat[treatment=='EE',desc :='Enhanced Efficiency']d02.treat[treatment=='CF',desc :='Combined fertilizer']d02.treat[treatment=='RES',desc :='Residue retention']d02.treat[treatment=='RFP',desc :='Fertilizer placement']d02.treat[treatment=='RFR',desc :='Fertilizer rate']d02.treat[treatment=='ROT',desc :='Crop rotation']d02.treat[treatment=='RFT',desc :='Fertilizer timing']d02.treat[treatment=='OF',desc :='Organic fertilizer']d02.treat[treatment=='RT',desc :='Reduced tillage']d02.treat[treatment=='NT',desc :='No tillage']d02.treat[treatment=='CC',desc :='Crop cover']# a list to store the coefficientsout2 = out3 =list()# make a for loop to do a main analysis per treatmentfor(i in d02.treat$treatment){if(i=='ALL'){# run without selection to estimate overall mean r_nue <-rma.mv(yi,vi, data=d02,random=list(~1|studyid), method="REML",sparse =TRUE) } else {# run for selected treatment r_nue <-rma.mv(yi,vi, data=d02[management==i,],random=list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list out2[[i]] <-data.table(mean =as.numeric(r_nue$b),se =as.numeric(r_nue$se),label =paste0(d02.treat[treatment==i,desc],' (n=',r_nue$k,')') )}# convert lists to vectorout2 <-rbindlist(out2)# plot for NUEforest(x = out2$mean,sei = out2$se, slab=out2$label, psize=0.9, cex=1, sortvar=out2$label, xlab="Change in NUE (%)", header="Treatment", col="#CC0000", lwd=2)
Warning in plot.window(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy, type, ...): "sortvar" is not a graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in box(...): "sortvar" is not a graphical parameter
Warning in title(...): "sortvar" is not a graphical parameter
Warning in int_abline(a = a, b = b, h = h, v = v, untf = untf, ...): "sortvar"
is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in axis(...): "sortvar" is not a graphical parameter
Warning in mtext(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Rank Correlation Test for Funnel Plot Asymmetry
Kendall's tau = -0.4545, p = 0.0447
#egger’s testregtest(out2$mean, out2$se)
Regression Test for Funnel Plot Asymmetry
Model: mixed-effects meta-regression model
Predictor: standard error
Test for Funnel Plot Asymmetry: z = -2.4494, p = 0.0143
Limit Estimate (as sei -> 0): b = 10.9299 (CI: 5.7644, 16.0955)
# Meta-regression for main factors# do a first main factor analysis for log response ratio for NUE# update the missing values for n_dose and p2o5_dose (as example)d02[is.na(n_dose), n_dose :=median(d02$n_dose,na.rm=TRUE)]# scale the variables to unit varianced02[,clay_scaled :=scale(clay)]d02[,soc_scaled :=scale(soc)]d02[,ph_scaled :=scale(ph)]d02[,mat_scaled :=scale(mat)]d02[,map_scaled :=scale(map)]d02[,n_dose_scaled :=scale(n_dose)]# what are the factors to be evaluatedvar.site <-c('mat_scaled','map_scaled','clay_scaled','soc_scaled','ph_scaled')var.crop <-c('g_crop_type','n_dose_scaled')var.trea <-c('fertilizer_type', 'crop_residue', 'tillage', 'cover_crop_and_crop_rotation', 'fertilizer_strategy')# i select only one example# the columns to be assessedvar.sel <-c(var.trea,var.crop,var.site)# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)# objects to store the effects per factor as wel summary stats of the meta-analytical modelsout1.est = out1.sum =list()# evaluate the impact of treatment (column tillage) on NUE given site propertiesfor(i in var.sel){# check whether the column is a numeric or categorical variable vartype =is.character(d02[,get(i)])# run with the main factor treatmentif(vartype ==TRUE){# run a meta-regression model for main categorial variable r_nue_1 <-rma.mv(yi,vi, mods =~factor(varsel)-1, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) } else {# run a meta-regression model for main numerical variable r_nue_1 <-rma.mv(yi,vi, mods =~varsel, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list: the estimated impact of the explanatory variable out1.est[[i]] <-data.table(var = i,varname =gsub('factor\\(varsel\\)','',rownames(r_nue_1$b)),mean =round(as.numeric(r_nue_1$b),3),se =round(as.numeric(r_nue_1$se),3),ci.lb =round(as.numeric(r_nue_1$ci.lb),3),ci.ub =round(as.numeric(r_nue_1$ci.ub),3),pval =round(as.numeric(r_nue_1$pval),3))# save output in a list: the summary stats collected out1.sum[[i]] <-data.table(var = i,AIC = r_nue_1$fit.stats[4,2],ll = r_nue_1$fit.stats[1,2],ll_impr =round(100* (1-r_nue_1$fit.stats[1,2]/r_nue_0$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(r_nue_0$sigma2)-sum(r_nue_1$sigma2))/sum(r_nue_0$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3) )}
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
# merge output into a data.tableout1.sum <-rbindlist(out1.sum)out1.est <-rbindlist(out1.est)# Meta-regression for main factors with interactions# make a function to extract relevant model statisticsestats <-function(model_new,model_base){ out <-data.table(AIC = model_new$fit.stats[4,2],ll = model_new$fit.stats[1,2],ll_impr =round(100* (1-model_new$fit.stats[1,2]/model_base$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(model_base$sigma2)-sum(model_new$sigma2))/sum(model_base$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3))return(out)}# update the database (it looks like typos)d02[tillage=='reduced', tillage :='no-till']d02[,fertilizer_type :=factor(fertilizer_type,levels =c('mineral','organic', 'combined','enhanced'))]d02[,fertilizer_strategy :=factor(fertilizer_strategy,levels =c("conventional", "placement","rate","timing"))]d02[,g_crop_type :=factor(g_crop_type,levels =c('maize','wheat','rice'))]d4 <-copy(d02)d4[,r4pl :=fifelse(fertilizer_strategy=='placement','yes','no')]d4[,r4ti :=fifelse(fertilizer_strategy=='timing','yes','no')]d4[,r4do :=fifelse(fertilizer_strategy=='rate','yes','no')]d4[,ctm :=fifelse(g_crop_type=='maize','yes','no')]d4[,ctw :=fifelse(g_crop_type=='wheat','yes','no')]d4[,ctr :=fifelse(g_crop_type=='rice','yes','no')]d4[,ndose2 :=scale(n_dose^2)]# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)r_nue_4 <-rma.mv(yi,vi,mods =~fertilizer_type + r4pl + r4ti + r4do + crop_residue + tillage + cover_crop_and_crop_rotation + n_dose_scaled + clay_scaled + ph_scaled + map_scaled + mat_scaled + soc_scaled + soc_scaled : n_dose_scaled + ctm:r4pl + ctm + ctw + ctr + ctm:mat_scaled + ndose2 -1,data = d4,random =list(~1|studyid), method="REML",sparse =TRUE)
Warning: Redundant predictors dropped from the model.
# show stats and improvementsout =estats(model_new = r_nue_4,model_base = r_nue_0)
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
print(paste0('model improved the log likelyhood with ',round(out$ll_impr,1),'%'))
[1] "model improved the log likelyhood with 32.9%"
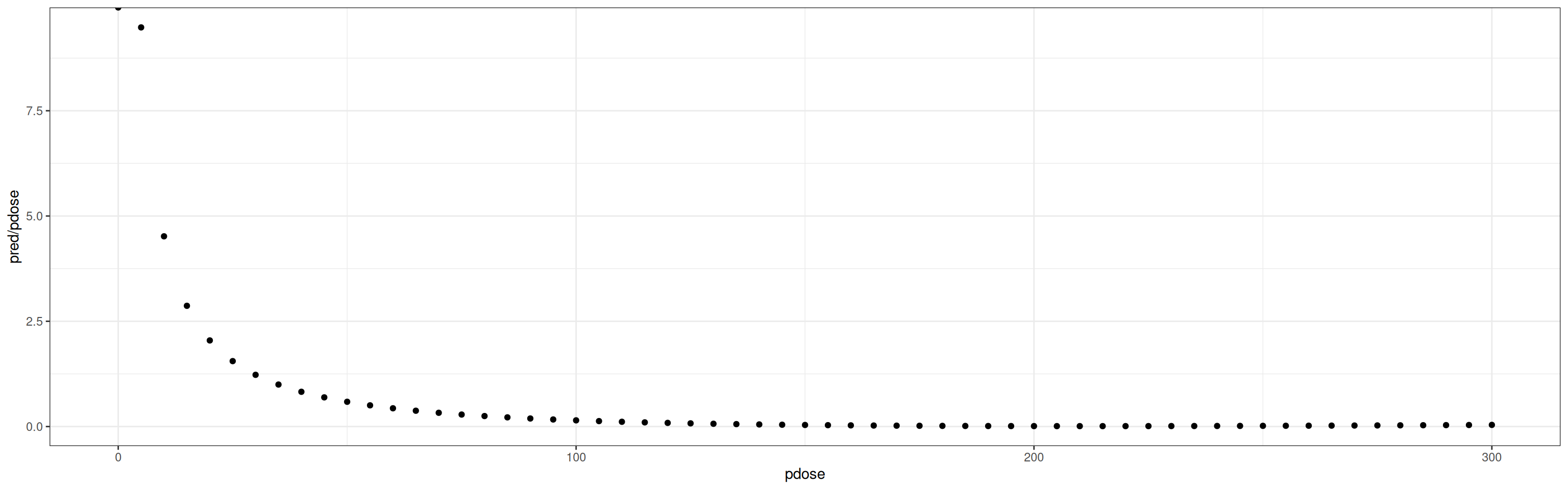
k <- r_nue_4$kwi <-1/r_nue_4$vivt <- (k-1) / (sum(wi) -sum(wi^2)/sum(wi))PR2 <- r_nue_0$sigma2 / (sum(r_nue_4$sigma2) + vt)# Model predictionsms =predict(r_nue_4,addx=T) # this is the order of input variables needed for model predictions (=newmods in predict function)cols <-colnames(ms$X)# make a prediction data.tabledt.pred <-as.data.table(t(ms$X[1,]))# set all variables to 0dt.pred[,c(cols) :=0,]# add the series of N dosedt.pred <-cbind(dt.pred,ndose =seq(0,300,5))dt.pred[,n_dose_scaled := (ndose -mean(d4$n_dose))/sd(d4$n_dose)]dt.pred[,ndose2 := (ndose^2-mean(d4$n_dose^2))/sd(d4$n_dose^2) ]# update the enhanced column (set to 1, all others are zero = non applicable)dt.pred[, fertilizer_typeenhanced :=1]# remove ndosedt.pred[,ndose :=NULL]# predict for EE and variable N dosem2 =predict(r_nue_4,newmods=as.matrix(dt.pred),addx=T) m2 =as.data.frame(m2)# plot prediction (now without confidence)# get the original Ndose herem2 =as.data.table(m2)m2[,pdose :=seq(0,300,5)]mean(d4$n_dose)
ggplot(data = m2,aes(x = pdose, y = pred/pdose)) +geom_point() +theme_bw()
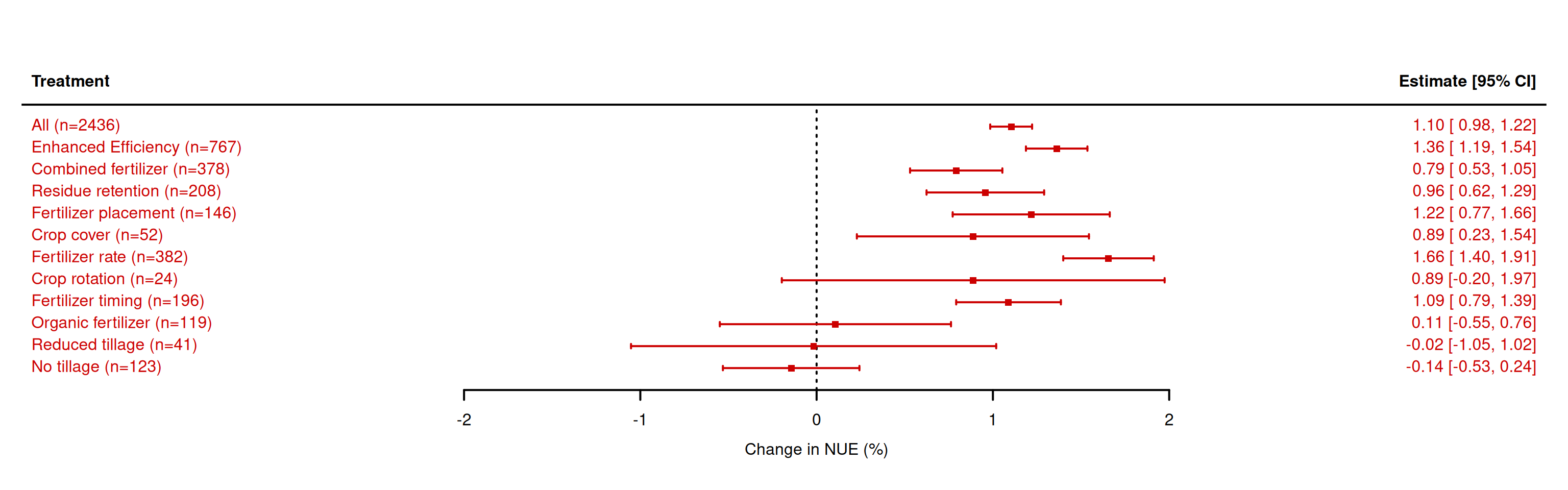
##################################### SMD (metafor) ####################################################theme_set(theme_bw())# read datad1 <- readxl::read_xlsx('Source Data.xlsx',sheet ="Tables")d1 <-as.data.table(d1)# Supplement the SD when missingd2<-d1CV_nuet_bar<-mean(d2$nuet_sd[is.na(d2$nuet_sd)==FALSE]/d2$nuet_mean[is.na(d2$nuet_sd)==FALSE])d2$nuet_sd[is.na(d2$nuet_sd)==TRUE]<-d2$nuet_mean[is.na(d2$nuet_sd)==TRUE]*1.25*CV_nuet_barCV_nuec_bar<-mean(d2$nuec_sd[is.na(d2$nuec_sd)==FALSE]/d2$nuec_mean[is.na(d2$nuec_sd)==FALSE])d2$nuec_sd[is.na(d2$nuec_sd)==TRUE]<-d2$nuec_mean[is.na(d2$nuec_sd)==TRUE]*1.25*CV_nuec_bar# clean up column namesd2 <-as.data.table(d2)setnames(d2,gsub('\\/','_',gsub(' |\\(|\\)','',colnames(d2))))setnames(d2,tolower(colnames(d2)))# calculate effect size (SMD)es21 <-escalc(measure ="SMD", data = d2, m1i = nuet_mean, sd1i = nuet_sd, n1i = replication,m2i = nuec_mean, sd2i = nuec_sd, n2i = replication )# convert to data.tablesd02 <-as.data.table(es21)# what are the treatments to be assessedd02.treat <-data.table(treatment =c('ALL',unique(d02$management)))# what are labelsd02.treat[treatment=='ALL',desc :='All']d02.treat[treatment=='EE',desc :='Enhanced Efficiency']d02.treat[treatment=='CF',desc :='Combined fertilizer']d02.treat[treatment=='RES',desc :='Residue retention']d02.treat[treatment=='RFP',desc :='Fertilizer placement']d02.treat[treatment=='RFR',desc :='Fertilizer rate']d02.treat[treatment=='ROT',desc :='Crop rotation']d02.treat[treatment=='RFT',desc :='Fertilizer timing']d02.treat[treatment=='OF',desc :='Organic fertilizer']d02.treat[treatment=='RT',desc :='Reduced tillage']d02.treat[treatment=='NT',desc :='No tillage']d02.treat[treatment=='CC',desc :='Crop cover']# a list to store the coefficientsout2 = out3 =list()# make a for loop to do a main analysis per treatmentfor(i in d02.treat$treatment){if(i=='ALL'){# run without selection to estimate overall mean r_nue <-rma.mv(yi,vi, data=d02,random=list(~1|studyid), method="REML",sparse =TRUE) } else {# run for selected treatment r_nue <-rma.mv(yi,vi, data=d02[management==i,],random=list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list out2[[i]] <-data.table(mean =as.numeric(r_nue$b),se =as.numeric(r_nue$se),label =paste0(d02.treat[treatment==i,desc],' (n=',r_nue$k,')') )}# convert lists to vectorout2 <-rbindlist(out2)# plot for NUEforest(x = out2$mean,sei = out2$se, slab=out2$label, psize=0.9, cex=1, sortvar=out2$label, xlab="Change in NUE (%)", header="Treatment", col="#CC0000", lwd=2)
Warning in plot.window(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy, type, ...): "sortvar" is not a graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in axis(side = side, at = at, labels = labels, ...): "sortvar" is not a
graphical parameter
Warning in box(...): "sortvar" is not a graphical parameter
Warning in title(...): "sortvar" is not a graphical parameter
Warning in int_abline(a = a, b = b, h = h, v = v, untf = untf, ...): "sortvar"
is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in axis(...): "sortvar" is not a graphical parameter
Warning in mtext(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in segments(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in plot.xy(xy.coords(x, y), type = type, ...): "sortvar" is not a
graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Warning in text.default(...): "sortvar" is not a graphical parameter
Rank Correlation Test for Funnel Plot Asymmetry
Kendall's tau = -0.3939, p = 0.0863
#egger’s testregtest(out2$mean, out2$se)
Regression Test for Funnel Plot Asymmetry
Model: mixed-effects meta-regression model
Predictor: standard error
Test for Funnel Plot Asymmetry: z = -1.9366, p = 0.0528
Limit Estimate (as sei -> 0): b = 1.7600 (CI: 0.9174, 2.6026)
# Meta-regression for main factors# do a first main factor analysis for log response ratio for NUE# update the missing values for n_dose and p2o5_dose (as example)d02[is.na(n_dose), n_dose :=median(d02$n_dose,na.rm=TRUE)]# scale the variables to unit varianced02[,clay_scaled :=scale(clay)]d02[,soc_scaled :=scale(soc)]d02[,ph_scaled :=scale(ph)]d02[,mat_scaled :=scale(mat)]d02[,map_scaled :=scale(map)]d02[,n_dose_scaled :=scale(n_dose)]# what are the factors to be evaluatedvar.site <-c('mat_scaled','map_scaled','clay_scaled','soc_scaled','ph_scaled')var.crop <-c('g_crop_type','n_dose_scaled')var.trea <-c('fertilizer_type', 'crop_residue', 'tillage', 'cover_crop_and_crop_rotation', 'fertilizer_strategy')# i select only one example# the columns to be assessedvar.sel <-c(var.trea,var.crop,var.site)# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)# objects to store the effects per factor as wel summary stats of the meta-analytical modelsout1.est = out1.sum =list()# evaluate the impact of treatment (column tillage) on NUE given site propertiesfor(i in var.sel){# check whether the column is a numeric or categorical variable vartype =is.character(d02[,get(i)])# run with the main factor treatmentif(vartype ==TRUE){# run a meta-regression model for main categorial variable r_nue_1 <-rma.mv(yi,vi, mods =~factor(varsel)-1, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) } else {# run a meta-regression model for main numerical variable r_nue_1 <-rma.mv(yi,vi, mods =~varsel, data = d02[,.(yi,vi,studyid,varsel =get(i))],random =list(~1|studyid), method="REML",sparse =TRUE) }# save output in a list: the estimated impact of the explanatory variable out1.est[[i]] <-data.table(var = i,varname =gsub('factor\\(varsel\\)','',rownames(r_nue_1$b)),mean =round(as.numeric(r_nue_1$b),3),se =round(as.numeric(r_nue_1$se),3),ci.lb =round(as.numeric(r_nue_1$ci.lb),3),ci.ub =round(as.numeric(r_nue_1$ci.ub),3),pval =round(as.numeric(r_nue_1$pval),3))# save output in a list: the summary stats collected out1.sum[[i]] <-data.table(var = i,AIC = r_nue_1$fit.stats[4,2],ll = r_nue_1$fit.stats[1,2],ll_impr =round(100* (1-r_nue_1$fit.stats[1,2]/r_nue_0$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(r_nue_0$sigma2)-sum(r_nue_1$sigma2))/sum(r_nue_0$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3) )}
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
# merge output into a data.tableout1.sum <-rbindlist(out1.sum)out1.est <-rbindlist(out1.est)# Meta-regression for main factors with interactions# make a function to extract relevant model statisticsestats <-function(model_new,model_base){ out <-data.table(AIC = model_new$fit.stats[4,2],ll = model_new$fit.stats[1,2],ll_impr =round(100* (1-model_new$fit.stats[1,2]/model_base$fit.stats[1,2]),2),r2_impr =round(100*max(0,(sum(model_base$sigma2)-sum(model_new$sigma2))/sum(model_base$sigma2)),2),pval =round(anova(r_nue_1,r_nue_0)$pval,3))return(out)}# update the databased02[tillage=='reduced', tillage :='no-till']d02[,fertilizer_type :=factor(fertilizer_type,levels =c('mineral','organic', 'combined','enhanced'))] d02[,fertilizer_strategy :=factor(fertilizer_strategy,levels =c("conventional", "placement","rate","timing"))]d02[,g_crop_type :=factor(g_crop_type,levels =c('maize','wheat','rice'))]d4 <-copy(d02)d4[,r4pl :=fifelse(fertilizer_strategy=='placement','yes','no')]d4[,r4ti :=fifelse(fertilizer_strategy=='timing','yes','no')]d4[,r4do :=fifelse(fertilizer_strategy=='rate','yes','no')]d4[,ctm :=fifelse(g_crop_type=='maize','yes','no')]d4[,ctw :=fifelse(g_crop_type=='wheat','yes','no')]d4[,ctr :=fifelse(g_crop_type=='rice','yes','no')]d4[,ndose2 :=scale(n_dose^2)]# run without a main factor selection to estimate overall meanr_nue_0 <-rma.mv(yi,vi, data = d02,random=list(~1|studyid), method="REML",sparse =TRUE)r_nue_4 <-rma.mv(yi,vi,mods =~fertilizer_type + r4pl + r4ti + r4do + crop_residue + tillage + cover_crop_and_crop_rotation + n_dose_scaled + clay_scaled + ph_scaled + map_scaled + mat_scaled + soc_scaled + soc_scaled : n_dose_scaled + ctm:r4pl + ctm + ctw + ctr + ctm:mat_scaled + ndose2 -1,data = d4,random =list(~1|studyid), method="REML",sparse =TRUE)
Warning: Redundant predictors dropped from the model.
# show stats and improvementsout =estats(model_new = r_nue_4,model_base = r_nue_0)
Warning: REML comparisons not meaningful for models with different fixed effects
(use 'refit=TRUE' to refit both models based on ML estimation).
print(paste0('model improved the log likelyhood with ',round(out$ll_impr,1),'%'))
k <- r_nue_4$kwi <-1/r_nue_4$vivt <- (k-1) / (sum(wi) -sum(wi^2)/sum(wi))PR2 <- r_nue_0$sigma2 / (sum(r_nue_4$sigma2) + vt)#######################################meta of meta-analytical data############################################################Load libraries library(ggplot2)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:data.table':
between, first, last
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(gridExtra)
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
library(cowplot)library(openxlsx)library(gg.gap)library(ggforce)library(data.table)malit <- readxl::read_xlsx('Source Data.xlsx',sheet ="meta_of_meta-analytica_data")malit <-as.data.table(malit)# create subset of columns we need (later subselection to match the df2)df <-data.frame(reference=malit$reference, ind_code=malit$ind_code, man_code=malit$man_code, man=malit$man, ind=malit$ind, man_type=malit$man_type, type.m=as.character(malit$type.m), n.S=1, dyr.1=malit$dyr.1, SEyr.1=as.numeric(malit$Seyr.1),unit=malit$unit, n.O=malit$n)# weighted meandf1 <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(type.m="Weighted mean", dyr.1 =weighted.mean(dyr.1, 1/SEyr.1),reference =paste0(reference, collapse =", "), n.S =n(), n.O =sum(n.O), man_type=first(man_type))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
df1 <-data.frame(df1)# weighted mean SE MINdf2 <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(type.m="Weighted mean SE", dyr.1 = (weighted.mean(dyr.1, 1/SEyr.1)-(1/sqrt(sum(1/SEyr.1)))),reference =paste0(reference, collapse =", "), n.S =n(), n.O =sum(n.O), man_type=first(man_type))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
df2 <-data.frame(df2)# weighted mean SE Maxdf3 <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(type.m="Weighted mean SE", dyr.1 =weighted.mean(dyr.1, 1/SEyr.1)+(1/sqrt(sum(1/SEyr.1))),reference =paste0(reference, collapse =", "), n.S =n(), n.O =sum(n.O), man_type=first(man_type))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
df3 <-data.frame(df3)# SE MINdf4 <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(type.m="Min and max SE", dyr.1 =min(dyr.1-SEyr.1),reference =paste0(reference, collapse =", "), n.S =n(), n.O =sum(n.O), man_type=first(man_type))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
df4 <-data.frame(df4)# SE MAXdf5 <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(type.m="Min and max SE", dyr.1 =max(dyr.1+SEyr.1),reference =paste0(reference, collapse =", "), n.S =n(), n.O =sum(n.O), man_type=first(man_type))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
df5 <-data.frame(df5)# find min and max individual means to write to output filedf_range <- df %>%group_by(ind_code,man_code,ind,man) %>%summarise(min_im =min(dyr.1), max_im =max(dyr.1))
`summarise()` has grouped output by 'ind_code', 'man_code', 'ind'. You can
override using the `.groups` argument.
# make a data frame with data we need from individual means with same column namesdf_im <-data.frame(reference=df$reference, ind_code=df$ind_code, man_code=df$man_code, ind=df$ind, man=df$man,man_type=malit$man_type, type.m=df$type.m, dyr.1=df$dyr.1, n.S=df$n.S, n.O=df$n.O)# use rbind to combine df_wm <-rbind(df_im, df1, df2, df3, df4, df5)df_means <-subset(df_wm, type.m=="Weighted mean")df_means <-data.frame(indicator=df_means$ind, management=df_means$man, man_type=df_means$man_type, wm =signif(df_means$dyr.1, digits=2))df_means <-cbind(df_means, min_im = df_range$min_im, max_im = df_range$max_im)df_wm$man <-factor(as.factor(df_wm$man), levels=c("Enhanced efficiency (A)","Fertilizer placement (4R)","Fertilizer timing (4R)","Fertilizer rate (4R)","Combined fertilizer (4R)","Organic fertilizer (4R)","No tillage (T)","Reduced tillage (T)","Residue retention (C)","Cover cropping (C)","Crop rotation (C)"))df_means